2026年5月20日,阿里云峰会现场,阿里巴巴正式发布通义千问最新旗舰模型——Qwen3.7-Max。这不是一次常规的版本迭代,而是国产大模型首次在Arena全球盲测中登顶第一、综合性能直追GPT-5.5与Claude Opus 4.6的里程碑事件。从3.5到3.7,三个月三次迭代,Qwen3.7-Max以万亿参数MoE架构、256K超长上下文、35小时全自主任务执行三大核心突破,重新定义了国产智能体的上限。本文将从性能排名、技术底座、实测能力、横向对比四大维度,全面拆解这款”国产最强”的真实实力。
延伸阅读:阿里万镜一刻深度测评:全链路AI视频创作平台,从剧本到成…、阿里 Qoder 1.0 深度解析:从 AI IDE 到…、MiniMax M3 vs DeepSeek V4 Pr…
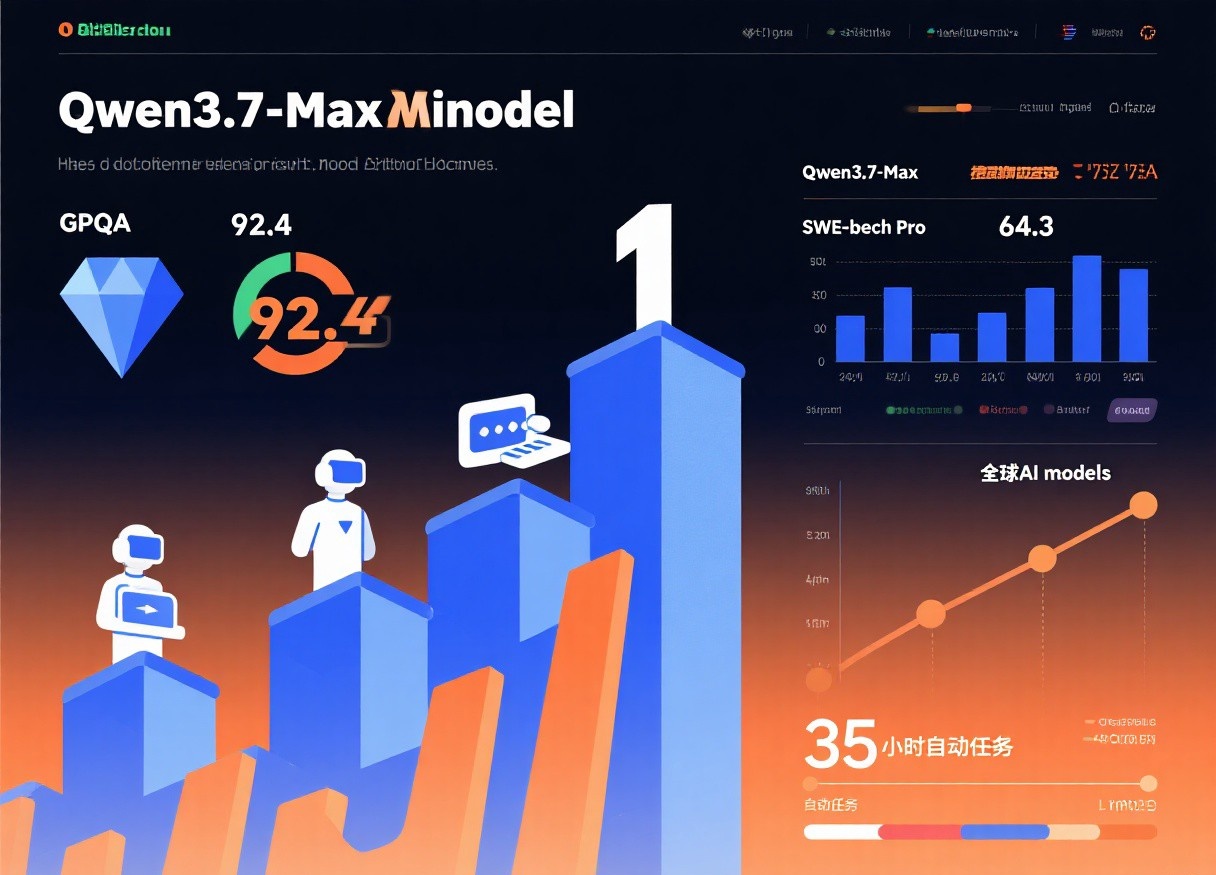
一、性能登顶:国产第一,全球第一梯队
Qwen3.7-Max的核心标签是”国产第一,全球顶尖”,权威评测数据硬核可查:
- Arena全球盲测:总榜超Kimi-K2.6、DeepSeek-v4-pro、GLM-5.1,位列国产第一、全球第13,是前15名中唯一的国产模型
- 数学能力全球第7:GPQA Diamond得分92.4,超越Claude Opus 4.6(91.3)
- 编程能力业界领先:SWE-Verified得分80.4,Terminal Bench 2.0达69.7
- 长程智能体:35小时全自主内核优化,1158次工具调用零人工干预,推理速度提升10倍
这意味着,Qwen3.7-Max已打破”国产模型弱于国际大厂”的固有认知,在核心能力上具备与GPT、Claude正面竞争的实力。
二、核心能力详解
2.1 编程智能体:全栈开发+工程级调试
Qwen3.7-Max在编程领域全面领先,覆盖从前端到后端、从单文件到多项目的全场景:
| 评测项目 | Qwen3.7-Max | Claude Opus 4.6 | DeepSeek-v4-pro |
|---|---|---|---|
| SWE-Pro | 60.6(第一) | 58.2 | 55.8 |
| SWE-Multilingual | 78.3(第一) | 72.5 | 68.4 |
| Terminal Bench 2.0 | 69.7(第一) | 65.3 | 62.1 |
| SciCode | 53.5(第一) | 51.9 | 48.7 |
实测能力包括:
- 全栈开发:支持HTML/CSS/JS前端、Python/Java后端、移动端App、桌面应用开发
- 工程级调试:自动定位代码Bug、分析报错日志、生成修复方案,支持多文件工程联动调试
- 代码优化:自主分析代码性能瓶颈,生成优化方案,实测可将Python脚本运行速度提升3-5倍
2.2 推理与知识:数学奥赛级+研究生水平
| 评测项目 | Qwen3.7-Max | Claude Opus 4.6 | GPT-5.5 |
|---|---|---|---|
| GPQA Diamond | 92.4 | 91.3 | 92.1 |
| HLE(人类最后一考) | 41.4 | 40.0 | 41.8 |
| SuperGPQA | 73.6(第一) | 71.2 | 72.8 |
| IFBench(指令遵循) | 79.1(第一) | 77.5 | 78.3 |
Qwen3.7-Max在数学推理上轻松解决IMO国际奥赛难题,4分钟给出正确答案;在研究生级别知识问答上同样表现出色。
2.3 MCP生态:工具调用能力统治级
| 评测项目 | Qwen3.7-Max | GLM-5.1 | Kimi K2.6 |
|---|---|---|---|
| MCP-Atlas | 76.4(第一) | 68.2 | 65.7 |
| MCP-Mark | 60.8(第一) | 54.3 | 52.1 |
| SkillBench | 第一 | 第二 | 第三 |
MCP(Model Context Protocol)是Agent时代的核心协议,Qwen3.7-Max在真实MCP使用场景中展现出极强的工具调用和联动能力。
2.4 35小时全自主任务:真正的”数字员工”
这是Qwen3.7-Max最颠覆性的能力——超长周期全自主任务处理。
测试场景:平头哥真武M890芯片内核优化 - 前提:无文档、无参考代码、无性能数据 - 过程:模型自主分析瓶颈、编写代码、调用编译工具、测试验证、迭代优化 - 耗时:35小时 - 工具调用:1158次 - 结果:推理速度提升10倍(vs 官方参考实现) - 对比:GLM 5.1(7.3倍)、Kimi K2.6(5.0倍)、DeepSeek V4 Pro(3.3倍)
整个过程中,模型还自主发起了关键架构重构,展现出接近人类工程师的长期自主工作能力。
三、技术底座:万亿MoE+自研芯片
3.1 万亿参数MoE架构
- 总参数超1万亿,采用混合专家(MoE)设计
- 每次推理仅激活约2200亿参数,兼顾性能与算力成本
- 256K超长上下文,可一次性处理20万字文档
- 思考预算控制:动态调整推理深度,用户可配置思考Token预算
3.2 真武M890芯片深度适配
- 与平头哥自研真武M890 AI芯片深度协同
- 硬件指令与模型算子完美匹配,推理延迟降低50%
- 形成”芯片-模型-云服务”全栈AI能力闭环
四、横向对比:六款旗舰模型全景
| 维度 | Qwen3.7-Max | GPT-5.5 | Claude Opus 4.7 | DeepSeek V4 | GLM-5.1 | Kimi K2.6 |
|---|---|---|---|---|---|---|
| 综合排名 | 国产第1 | 全球第1 | 全球第2 | 国产第2 | 国产第3 | 国产第4 |
| 编程能力 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 数学推理 | 92.4 | 92.1 | 91.3 | 88.5 | 85.7 | 91.0 |
| Agent能力 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 中文写作 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 长上下文 | 256K | 270K | 1M | 128K | 128K | 200万字 |
| API价格 | 低 | 高 | 高 | 极低 | 中 | 中 |
4.1 选型建议
| 场景 | 首选 | 理由 |
|---|---|---|
| 复杂编程 | Claude Opus 4.7 | SWE-bench Pro 64.3%,代码仓库理解最强 |
| Agent任务 | GPT-5.5 | Terminal-Bench 82.7%,工具调用最稳定 |
| 中文写作 | Qwen3.7-Max | 中文语料积累深厚,逻辑连贯性最佳 |
| 长文档分析 | Kimi K2.6 | 200万字超长上下文,独一档 |
| 性价比 | DeepSeek V4 | 价格仅为GPT-5.5的1/35 |
| 国产合规 | Qwen3.7-Max | 本土适配、数据安全、成本可控 |
五、落地场景与价值
5.1 企业级应用
- 办公自动化:通过MCP集成与多智能体协作,自动处理邮件、生成报表、会议纪要、合同审核
- 代码开发:全栈开发、代码审查、Bug修复、性能优化
- 数据分析:自动清洗数据、生成可视化报告、洞察业务趋势
5.2 开发者工具
- AI编程助手:IDE插件、代码补全、智能提示
- 自动化测试:生成测试用例、执行回归测试
- 文档生成:自动撰写技术文档、API文档
5.3 个人用户
- 学习助手:解答数学难题、辅导编程、翻译文献
- 内容创作:撰写文章、生成文案、创作小说
- 生活助手:日程管理、旅行规划、购物决策
六、总结:国产大模型的里程碑
Qwen3.7-Max的发布,标志着中国大模型正式跻身全球第一梯队,打破海外模型的垄断格局。它不仅是”国产之光”,更以更强的本土适配、更优的智能体能力、更稳的安全合规、更低的落地成本,成为国内个人、开发者、企业的首选AI模型。
三个月三次迭代,从3.5到3.7,阿里千问展现出惊人的进化速度。而35小时全自主任务的实测,更是证明了国产模型在Agent时代已经具备了与国际巨头正面竞争的实力。
对于国内用户而言,Qwen3.7-Max不是”勉强能用”,而是”天生适配”。它省去了海外模型的本地化改造成本,提供了更符合国内场景的智能体能力,是真正意义上的”国产最强旗舰”。